A while ago, I was enjoying the Hackernewsletter, and I got amused by how two items of that edition caught my attention :)
The first one was request-html, which binds the requests Python library to a real browser. It can be pleasant for scraping websites, end-to-end testing of Web applications or turning websites into APIs. It reminded me Spynner, that Kiorky wrote like 8 years ago. And obviously our esteemed CasperJS <3
The second one was 6 degrees of Wikipedia, which builds a graph database of links between articles. It's absolutely fascinating! You can see how many «navigation paths» exist between two notions for example. By the way did you know that there are 2306 ways to navigate from Barbara Streisand to the Erlang programming language in 4 steps? I'm sure you'll be able to make use of that at your next family dinner.
It reminded me a funny Youtube video where the guys play some «Wikipedia navigation» games. Like both players open a random article, the winner is the first one to reach the opponent's article by only following links from one page to another. Or both players open a random article, and the first one to reach the «Philosophy» page wins.
While being bored at the airport, I dediced to go for a microhack! I will write a small script to figure out how many hops it takes in average to go from any article to the Philosphy page. And following the first link of the article like in the Youtube video...
pipenv install requests-html --python=python3.6
Let's reach the body of a Wikipedia random page first:
from requests_html import HTMLSession
root = 'https://fr.wikipedia.org'
random_page = '/wiki/Sp%C3%A9cial:Page_au_hasard'
session = HTMLSession()
r = session.get(root + random_page)
print(r.html.find("body", first=True))
Ok, it works and the API seems to be made for humans ;) Let's find out what would be the right CSS selector to pick the first link of the article:
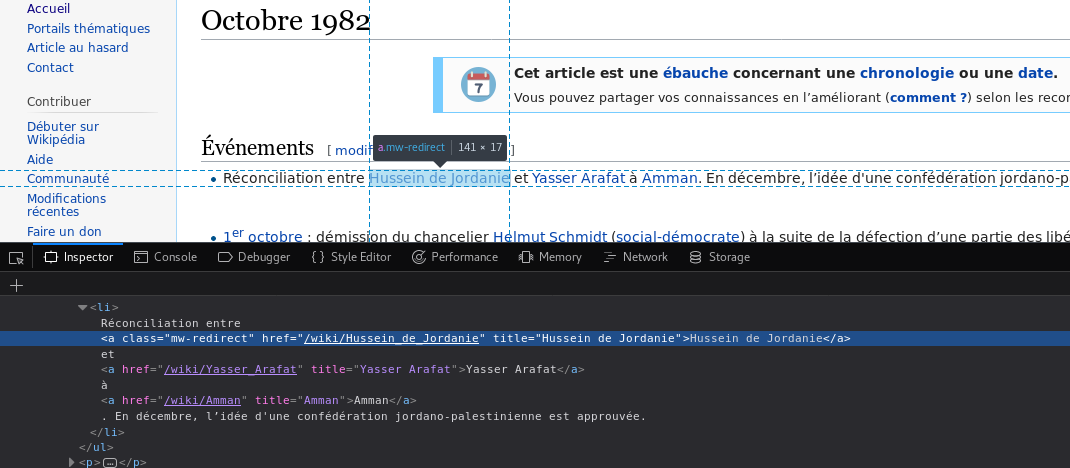
Something like #mw-content-text a?
But that sometimes picks the summary section on the right side. Be more hackish and precise:
#mw-content-text > .mw-parser-output > p > a[href^='/wiki'],
#mw-content-text > .mw-parser-output > ul > li > a[href^='/wiki']
This code will be probably broken by the time you read that article, but I don't care! The joy of microhacks, not the joy of scraping, remember.
Now let's iterate until the link points to the Philosophy page:
SELECTOR = ("#mw-content-text > .mw-parser-output > p > a[href^='/wiki'],"
"#mw-content-text > .mw-parser-output > ul > li > a[href^='/wiki']")
url = random_page
while "first link is not philosophy":
r = session.get(root + url)
link = r.html.find(SELECTOR, first=True)
title = link.attrs['title']
print(title)
if title == 'Philosophie':
break
url = link.attrs['href']
Cool it works!
$ pipenv run python dop.py Jeu vidéo Jeu électronique Jeu Psychisme Conscience Philosophie
Now let's repeat that for a hundred random pages, cache already visited links and compute average of degrees.
results = []
cache = {}
while len(results) < 100:
degrees = []
url = random_page
while "first link is not philosophy":
if len(degrees) > 1 and url in cache:
link = cache[url]
else:
r = session.get(root + url)
link = r.html.find(SELECTOR, first=True)
if link is None:
break # bad selector
cache[url] = link
title = link.attrs['title']
if title in degrees:
break # loops
degrees += [title]
if title == 'Philosophie':
results.append(len(degrees))
print(len(degrees), " - ".join(degrees))
break
url = link.attrs['href']
print(float(sum(results)) / len(results), min(results), max(results))
I can now tell you that if you keep clicking on the first link of a random article you'll reach the Philosophy page with 13.45 steps in average. We could also have run a few workers in parallel.
Pretty useful huh!?
It was that or hang around in gear shops where I'd never buy anything anyway...
#microhack - Posted in the Dev category