When I started to write the first lines of this article, it was the last day of Ethan in our team. His departure marked the end of an era that I'll try to tell you about here.
Prehistory (~2014)
While I was working at Makina Corpus, we were regularly coming up with the same kind of architectures: a database, a REST API, and frontend/mobile stuff. Other teams were also starting to consider the idea of «headless CMS».
I wanted to build a reusable backend, where you define your models in JSON and retrieve/store records. Alexis and I wrote down some pseudo code at a DjangoCon and we started the Daybed project, using Pyramid. It became functional and I even talked about it at FOSDEM.
Alexis, Rémy, and Tarek were building Web APIs in the Cloud Services team at Mozilla, and there were needs to offer remote storage features to Firefox OS app developers.
I was hired onto their team and we were about to roll out our first app: a «reading list» service (à-la Pocket).
Neolithic (2015-2016)
The team had accumulated a lot of experience with Web APIs, and one thing was certain: we shouldn't start each project from scratch. Even though we had a secret plan (a reusable service), we couldn't justify starting with that.
We gathered a lot of good practices and a handful tooling in one library: Cliquet. We hated the word «framework», but at least we wanted a standard way of building services (cf. introduction blog post or talk at PyBCN).
Cliquet had the notion of pluggable storage backends. And, because we had this vision of reusable services, we built a proof-of-concept where a service built with Cliquet would be storing its data in another service built with Cliquet 🤯 [1].
Eventually, this storage service became Kinto, and Cliquet became kinto.core.
n1k0 and Magopian joined the team, and built a nice offline-first SDK for Kinto. Plus a generic UI to CRUD records of any accessible Kinto server (kind of remote phpmyadmin). In order to generate forms from collections JSON schema, they released react-jsonschema-form (which now has like 9k stars on Github!).
This was an exciting time! Kinto was on Hacker news, and the number of Github stars was going up!
At this time, there were many other challengers in the field of offline-first apps and backends as a service, and we were pretty close to them. Michiel de Jong, the spec author of Remote Storage, joined Mozilla and was briefly in our team. Dale Harvey was already at Mozilla and was doing PouchDB. Luca Marchesini, a Fullstack Fest friend, was also working on Kuzzle.
But internally in the company — above Tarek (our manager) — we were not able to defend our vision very well. Mozilla didn't seem ready to explore the dangerous grounds of hosting user data, at least not beyond Firefox Sync. And meanwhile, Kinto was still being mentioned as the Mozilla response to Facebook Parse and Google Firebase (completely inaccurate of course, because Kinto was never an official Mozilla project).
Luckily, shortly after, the *Go Faster* initiative was started, with the goal of shipping changes to Firefox faster than the current release cycle. If our system could synchronize user data between devices, then it could obviously do a uni-directional synchronization of read-only data from one admin to millions of clients. That's how we started to use Kinto to publish the malicious addons blocklist, the certificates revocation list, and some assets for Firefox Android, independently from release trains.
The Kinto client SDK was now in Firefox, and hundreds of millions of clients were pulling data from our servers at https://firefox.settings.services.mozilla.com.
Antiquity (2016-2018)
We were contributing to Gecko in the mozilla-central repo, and that was not so common for a team in the Cloud Services org. Mercurial, old-style JS, C++, XPCOM... we were not comfortable at all.
Ethan joined the team. He implemented the chrome.storage Web Extension API using Kinto, and suddenly we were storing addons preferences of users (carefully encrypted on the client side of course).
Kinto now had several use-cases within Firefox. However, clearly, we still hadn't reached any critical mass. It was just another arrow on diagrams.
It was a boring and frustrating phase. Pushing the required configuration changes for each new use case. A lot of back and forth with the Ops for root objects manipulations. Responsibilities were limited.
We knew we could do much more, any piece of configuration or JSON in the repository could be migrated to our system! We could use it for internationalization! But we were not good door-to-door salesmen. Feedback, positive or negative, was almost nonexistent.
The revolutionary ideals of our initial team were fading away. We had to admit that we failed at promoting our vision of a user-facing storage backend (see Thoughts section). Self hosting, decentralized Web, Tor hidden services, were conversations at night around a drink, not in meeting rooms anymore. I'm pretty sure Mozilla even had a few projects running on Google Firebase at this time.
At the end of that period, most members of the original team had left, disillusioned. Ethan and I were the last «Kinto guys» at Mozilla.
Fortunately we had dependabot enabled on our repos so we don't look too lonely.
Modern Age (2018-2020)
In December 2016, we made a list of all the sources where Firefox would pull data from. No spoiler, it was too long.
Our goal was to unify several of these communication channels into one, and to start demanding a good reason to justify rolling out a new update source.
For most use-cases in Firefox, the Kinto API was too low level, and doing too much. As an example, the certificate configuration for signature verification was unnecessarily complex. And there was no official cookbook.
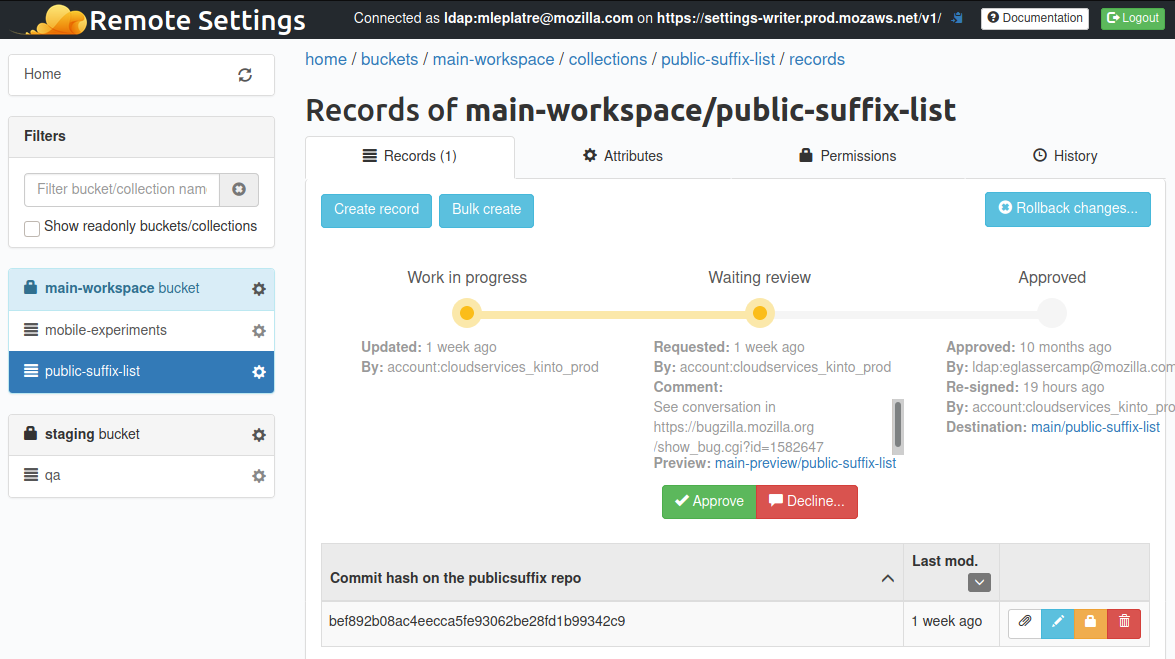
Our new manager Benson was defending the idea of Remote Settings. Two methods: .get() and .on("sync", ...). New collections of records had to be self-service, because we were not going to be able to continue the manual onboarding.
We had all the pieces in place to achieve that, it was mostly about improving developer experience. We refactored a number of things, added OAuth support, and Ethan integrated our clients and server with the broadcast service for push notifications. We morphed the existing client integrations into a high level generic API, available for any component in Firefox. And on the server side, the original Kinto Admin had everything in its DNA to become the Remote Settings Admin UI.
In December 2018, I presented Remote Settings in front of hundreds of Firefox developers! This felt energizing and great! On the other hand, I knew I was reaping the rewards of our team mates who had left.

We merged with the SHIELD team and were now part of the Product Delivery team. Now responsible of making off-train changes reliable and safe (ie. updates without reinstall).
Since we were only pulling read-only data from the server, the whole offline bi-directional sync code was overkill and slightly inefficient. For the sake of simplicity, I got rid of the Kinto offline library in Firefox and replaced it with plain Gecko specific IndexedDB code. Way easier to reason about, especially for a future code reader who wouldn't have the back story.
More and more critical components of Firefox, desktop or mobile, are now relying on Remote Settings. A/B testing, experiments metadata, user messages, features recommandations rules, list of password breaches for Firefox Monitor, password fields detection rules, localization packages, search partners configuration... All of them using our two methods API :)
We could not have been more successful. Remote Settings had become THE standard way to ship data in Firefox outside release trains! Some of us sometimes still call it Kinto.
In Summer 2020, there are approximately fifty collections on the server. The reliability of the pipeline is my main responibility, and to have a better overview of the whole thing, I mainly rely on two things: a unified client Telemetry, and a monitoring tool: Poucave, that I'll present in another post.
Futurism (2021-)
Futurewise, the next obvious part is the Rust client, in order to have a unified experience across platforms, using a ~single code base :)
There was an initiative recently to unify our experimentation solutions between desktop, mobile, websites, and other products. During their study, they legitimately asked why use Remote Settings to ship experiments metadata, and not JSON files behind a CDN.
The question is legitimate, and we could defend our pipeline because we have a validated security workflow, with VPN access, permissions management, some review and signoff features, push notifications, diff-based synchronization, content signature verification...
Nevertheless, at the same time, more and more use-cases are server-to-server or have automated publication from scripts. And some even built their own UI.
Maybe our Remote Settings service could be achieved with just something like a Git repo, static data, and a CDN in front.
Clients pull blobs and content signatures from a URL, each use-case being responsible of parsing these binaries as JSON or using them as plain resources or files. Permissions setup could be achieved using protected branches and submodules in the repo. No more UI to maintain, the reviewing process would just happen upfront, before merging the pull-request. No more backend and database with records and fields, just a few scheduled tasks or commit hooks.
A dumb pipe of static data, with complex workflows outside the system itself. A little bit like this blog actually.
Why not!
Thoughts
I hope this long article helped you understand how a long term project can evolve and mutate. I thought it would be interesting to see it from within a company like Mozilla, often mentioned in headlines.
What made the success?
Remote Settings became a critical part of Firefox. Clearly, since it is leveraging only a subset of Kinto, the success can be largely attributed to the vision and efforts of our early team. We're still friends and I'm super proud of what we accomplished! Big up!
We have the very early days in memory, when Tarek had managed to free some of our time so that we could build prototypes and demos. Later, Benson took over and embraced our vision. Both were advertising the idea of a reusable service within the company while we were busy coding!
The patience of stakeholders who held our hand in order to land patches in Firefox massively contributed to the success. Special thanks to Gijs, Lina, Florian, Standard8...
I believe it is also important to highlight how important our first «customers» were to the growth and adoption of Remote Settings. The security/crypto teams and the Activity Stream (now UJET) deserve much credit (mgoodwin, Nanj, JCJ, Ricky, Andrei...). Their advocacy for the solution and working closely with us to make it better made a big difference.
Another factor is that we were consistently protecting the functional scope of the system. It is a data pipe: publish data on one side, reach the target audience reliably. It took a lot of effort to say «no», and keep the complexity trend downwards, instead of building dedicated features for specific use-cases.
These previous two combined — motivated early adopters and product focus — were crucial in adoption. We were able to provide a good customer service because we had participated in the early integrations and implementations for other teams. When new use-cases were joining us, we almost had everything covered already.
During our company meetings, we were making sure we would spend more time with people, and the least in front of computers. I don't cross the world to do what I can do from home! We had joyful moments and this happiness certainly contributed to the success :) Through the numerous use-cases, I got to know many teams in the company, and always worked in a fantastic atmosphere. I am happy to help, they seem happy with the solution, it is great!
What about Kinto?
I don't want this article or section to sound like a retrospective of Kinto itself, but I think there are a few important things to underline.
The Kinto organization is relatively quiet, but we have users, and Dylan is dedicating an amazing amount of energy on the project! A lot of engineers at Mozilla are going to benefit from his efforts to migrate the Admin UI to Bootstrap 4 (3 years after the PR was started 🤣)! Kudos!
Nevertheless, we cannot deny that the Kinto community is not as flourishing as it used to be ;) And let's be clear: from the Mozilla standpoint, Kinto is just an implementation detail.
If I win the lottery and leave (the positive version of the bus factor idea), there is no guarantee that the next pair of eyes taking a fresh look at the Remote Settings architecture or the Kinto code base will decide to keep it. In other words, as long as Kinto is used in Remote Settings, the project will be maintained and be taken care of. Mozilla will continue to invest in Kinto as long as it has value and makes sense.
What if I had to do it over again?
If someone would have come to us 5 years ago with the needs of a solution to update parts of Firefox without reinstall, what would we have done?
If we wouldn't have been desperate to «sell» Kinto internally, would we have used a database as-a-service with a CRUD API?
Alexis started Pelican — a static blog generator — around 2011, 4 years before we were working on the first use-cases. I find it extremely ironic that the solution described in the Futurism section would basically consist in applying the same principles to publish read-only data 🙃 [2]
The current approach also has a downside that I realized only very recently. Before, if someone wanted to contribute a new password recipe in Firefox, they would just have to add a line in the .json and get their patch approved. Now the source of truth is the Remote Settings server. Adding a recipe means opening a ticket to request it, and a stakeholder to connect on the VPN and add it. If the source of truth was the repo, with jobs to publish data online for live updates, it would probably make more sense. Plus, it would save forks or the Thunderbird team to run their own Remote Settings instance...
In 2015, JSON was everywhere and a pretty natural choice. But we had to complement it with a notion of attachments for heavy content. Today, I would probably consider going full binary for everything. JSON was problematic for content signatures, since there are many ways to serialize it (Unicode strings and float numbers, the worse!). Something like CBOR may have helped.
Generally speaking — and here comes the self-flagellation part — I think that we could have done a better job if we would have studied more past research. As James Long wrote, «If you're excited about an idea, it's super tempting to sit down and immediately get going. But you shouldn't do that until you've done some cursory research about how people have solved it before.». In our case, we could have considered using CRDTs to sync data, Merkle trees for content signatures of partial diffs, or all the things available from the video games industry to update assets etc... and this is true for specifications too. I now think we made a big mistake when we decided to deviate from the Remote Storage spec while Michiel was in our team. Same with our custom Canonical JSON.
With regards to Kinto itself, it shows that the idea itself does not have much value (I wrote about that already). Kinto was a very good idea, and we could develop it to a certain point. We were experienced with code, but our limits became the limits of the project: we were very unfit to pitch ideas and do product marketing.
On the front of data sovereignity, great minds like Sir Tim Berners-Lee are working on it, and the need of a reusable backend for Web developers hasn't disappeared. Appwrite and kuzzle (👏) seemed to be relevant open source solutions in 2020! I don't know about other projects like https://backendless.com/ or http://hood.ie/ though. Among the last challengers, PostgREST and Hasura seem to be doing great.
But hey, in the precise context of Remote Settings, these solutions may not have fit anyway!
| [1] | Rémy reapplied a similar concept to build SyncTo, a bridge from Kinto to Firefox Sync for Firefox OS developers. |
| [2] | Ethan and n1k0 say that we had considered this idea. We can't recall why we discarded it. Maybe because we were too obscessed about selling Kinto internally? Or limitations of our signing infrastructure behind the VPN? |
#mozilla, #python, #kinto - Posted in the Dev category